Introducción a Python y gráficos¶

Contenidos¶
- Introducción a conceptos básicos de Python
- Librerías a usar:
- Tipos de gráficos
- Dar formato a gráfico
Python¶
Python es un lenguaje de programación interpretado multiparadigma.
- Creado a fines de los 80 por Guido von Rossum.
- El nombre del lenguaje proviene de la afición de su creador por los humoristas británicos Monty Python.

Características¶
- Facilidad de escritura y lectura$^1$.
- Compatibilidad en en múltiples sistemas operativos (portabilidad).
- Extensibilidad.
- Código abierto.
1: Cuando está bien escrito
# Acá irían ejemplos básicos
Tipos de datos en Python¶
# Strings
"Instituto de Investigación y Desarrollo en Ingeniería de Procesos y Química Aplicada - IPQA"
# Números enteros
5
# Números flotantes
1.249
# Listas
[1, 2, 3, 4]
# Diccionarios
{
"nombre": "Federico Benelli",
"edad": 27,
"cursos": ["Termodinámica y Comportamientos de Fases de Fluidos en Ingeniería",
"Diseño de Software Científico"]
}
{'nombre': 'Federico Benelli',
'edad': 27,
'cursos': ['Termodinámica y Comportamientos de Fases de Fluidos en Ingeniería',
'Diseño de Software Científico']}
Operaciones¶
# Suma/Resta
1 + 2
# Multiplicación
2*2
# Potencia
2**2
4
En todos los casos se respeta el orden de precedencia esperable de las operaciones matemáticas:
Paréntesis $\rightarrow$ Potencias $\rightarrow$ Productos $\rightarrow$ Sumas
Comparaciones lógicas¶
1 == 1 # Igualdad
2 != 1 # Desigualdad
1 < 2 # Menor a
2 > 1 # Mayor a
2 <= 1 # Menor o igual a
1 >= 1 # Mayor o igual a
True
Cómo interperta Python estas operaciones?¶
# Hacer ejemplos simples interactivos de operaciones y comparaciones,
# y hablar de variables
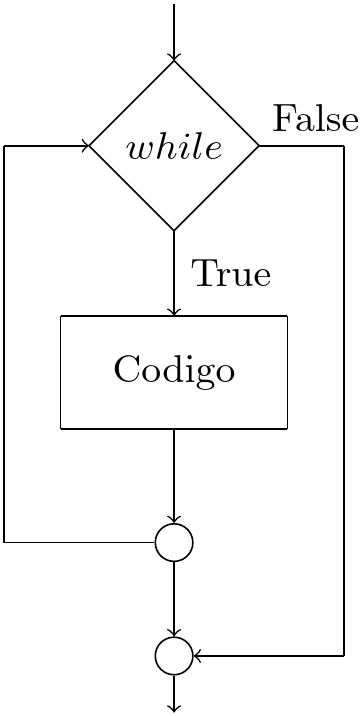
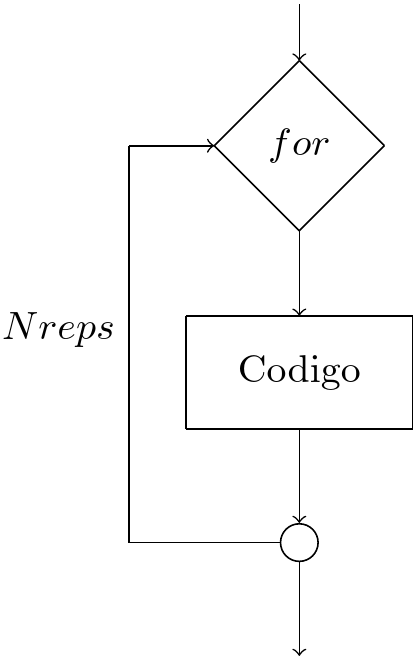
Control de flujo de código¶
El flujo del código se controla mediante operadores condicionales
if, else y elif
Y mediante operadores iteradores
for, while
Operadores condicionales¶
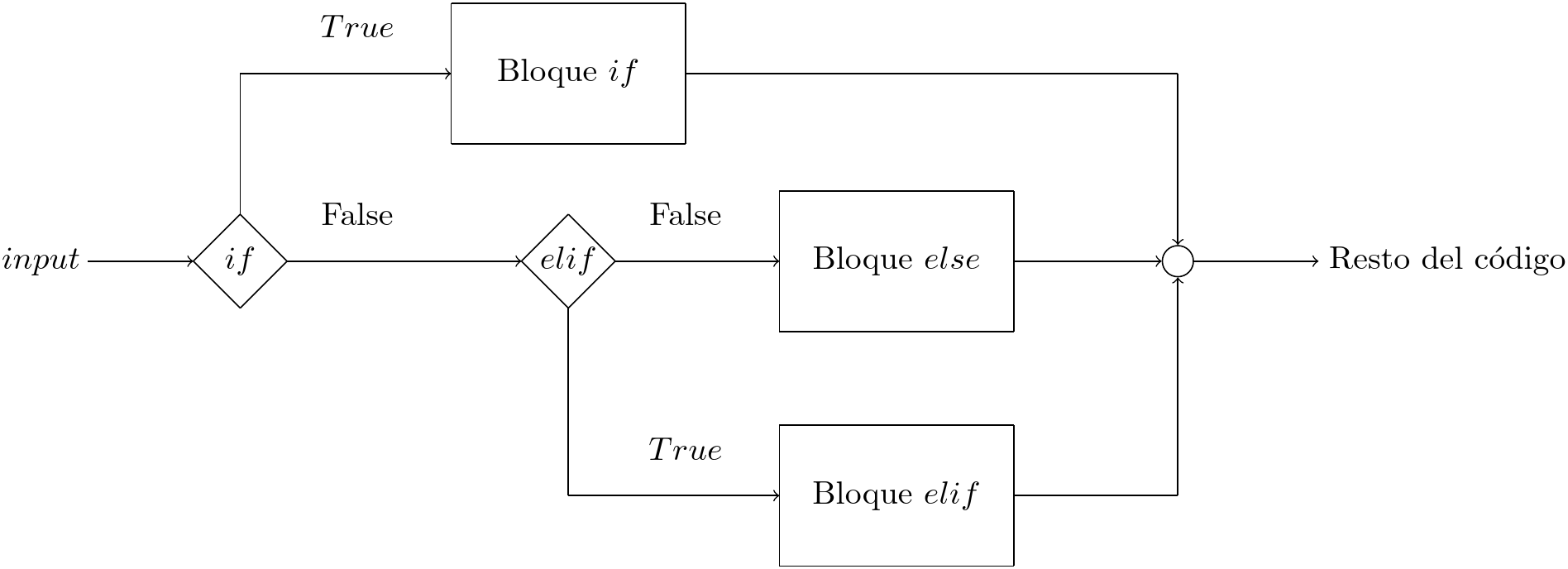
# Ejemplo de flujo condicional
porcentaje_tesis = 50
if porcentaje_tesis < 50:
print('Falta bastante...')
elif porcentaje_tesis <= 75:
print('Falta un cachito...')
elif porcentaje_tesis < 100:
print('Ya casi ya casi!')
else:
print('Se terminó!!')
Falta un cachito...
# Ejemplos
Funciones¶
Para simplificar el código pueden definirse funciones, las cuales reciben un input (o no) y realizan operaciones.
Siempre devuelven un valor! De no especificarse devuelven un valor Nulo NoneType
Python posee por defecto funciones de utilidad
print() # Imprime en pantalla el valor dado
abs() # Valor absoluto
round() # Redondeo de números flotantes
min() # Valor mínimo de una lista
sorted() # Ordena una lista
sum() # Sumatoria de una lista
len() # Largo de una lista
type() # Tipo de variable
# Acá se muestra como funcionan las funciones de manera práctica
Definición de funciones¶
Además de las funciones predeterminadas de Python, se pueden definir todas las funciones que se deseen.
def cuadratica(x, a, b, c):
"""Calcula un polinómio cuadrático en el valor x dado
args:
x (float): Valor de x donde calcular
a,b,c (float): Coeficientes cuadráticos
returns:
y (float): Función cuadrática valuada en x"""
y = a*x**2 + b*x + c
return y
cuadratica(1, 1, 2, 4)
7
X = []
Y = []
a, b, c = 2, 4, 6
for x in range(10):
# Valuar función en x y asignar a variable `y`
y = cuadratica(x, a, b, c)
# Concatenar valor de x a lista de Xs
X.append(x)
# Idem y
Y.append(y)
if y > 100:
print('El valor de y superó 100!')
print('y=', y)
break
print(X)
print(Y)
El valor de y superó 100! y= 102 [0, 1, 2, 3, 4, 5, 6] [6, 12, 22, 36, 54, 76, 102]
Librerías¶
Una de las características de Python es su extensibilidad por medio de librerías.
Las librerías son conjuntos de métodos, funciones, variables. Generadas para cumplir funciones particulares, en el ámbito científico destacan:
numpy: Cálculo vectorial.scipy: Conjunto de librerías de uso científico, como estadística y cálculo matemático.pandas: Interpretación de datos.matplotlib: Generación de gráficos
Evolución de desarrollo de librerías¶
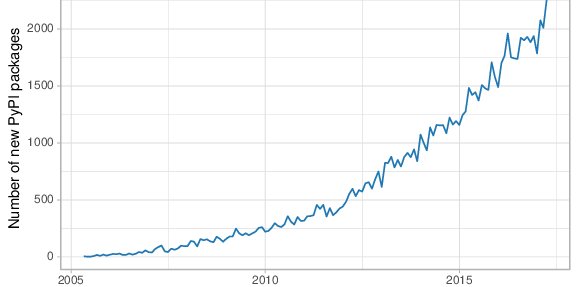
Generación de gráficos en Python¶
La variedad de gráficos que se pueden realizar en Python es superlativa.
Solo basta con entrar a la galería de ejemplos de matplotlib para darse una idea de lo extenso que es. Y es una librería sola!
Además de matplotlib existen otras librerías que se utilizan para generar gráficos, como:
plotlyseabornbokeh
Aquí se van a ver conceptos básicos de matplotlib
Importación de librerías¶
En primera instancia, se importan librerías de interés.
import matplotlib.pyplot as plt # Gráficos
import pandas as pd # Tratamiento de datos
# Todo el código dentro de la presentación es interactivo
# la idea es mostrar primero el concepto básico y de ahí ir incrementando el detalle:
# cambiar colores, agregar leyendas, escalas, múltiples datos, etc.
Gráficos de línea¶
x = []
for i in range(10):
x.append(i)
y = [xi**2 for xi in x]
plt.plot(x,y)
plt.show()

Gráficos de dispersión¶
plt.scatter(x,y)
plt.show()

Barras¶
x = ['asd', '2', '3']
y = [5, 10, 90]
plt.bar(x,y)
plt.show()

Formato extra¶
x = []
for i in range(-100,100):
x.append(i)
y = [xi**2 for xi in x]
y0 = 0
x0 = 0
plt.rcParams['font.family'] = 'Trebuchet MS'
plt.rcParams['font.size'] = 12
fig = plt.figure(figsize=(5,5))
plt.plot(x,y, label = '$x^2$')
plt.title('Gráfico de $f(x) = x^2$')
plt.ylabel('$f(x)$')
plt.xlabel('$x$')
plt.xlim(-10,60)
plt.ylim(-50,4000)
plt.annotate('Mínimo global',
xy=(x0, y0), xycoords='data',
xytext=(0.5, 0.5), textcoords='axes fraction',
color='orange',
arrowprops=dict(arrowstyle='->', color='black'),
horizontalalignment='left', verticalalignment='top',
)
plt.grid(color='lightgray')
plt.legend()
plt.show()

Caso aplicado¶
Se realizaron extracciones con distintos solventes (orgánico/inorgánico) y medios (ácido/básico)
Se desea generar gráficos de caja con desvíos comparando las extracciones en distintas fases
# Importación de librerías
import pandas as pd # Lectura de datos tabulados (almacenados en un archivo Excel)
import numpy as np # Procesamiento de números
import matplotlib.pyplot as plt # Gráficos
import seaborn as sns # Complemento para gráficos
# Lectura de datos
df=pd.read_excel('ensayos.xlsx', index_col=0, engine='openpyxl')
df
| Repeticion | Fase | Masa Total (g) | Cantidad AC (g) | Rendimiento | Pureza | |
|---|---|---|---|---|---|---|
| Ensayo | ||||||
| Ensayo 1 | 1 | Extracto | --- | 0.155571 | --- | --- |
| Ensayo 1 | 1 | Fase Orgánica | 0.104 | 0.009500 | 6.10654 | 9.13462 |
| Ensayo 1 | 1 | Fase Acuosa | --- | 0.001000 | 0.642794 | --- |
| Ensayo 1 | 2 | Extracto | --- | 0.167895 | --- | --- |
| Ensayo 1 | 2 | Fase Orgánica | 0.185 | 0.013000 | 7.74296 | 7.02703 |
| Ensayo 1 | 2 | Fase Acuosa | --- | 0.004000 | 2.38245 | --- |
| Ensayo 2 | 1 | Extracto | --- | 0.194233 | --- | --- |
| Ensayo 2 | 1 | Insolubles en agua | 0.132 | 0.011000 | 5.66332 | 8.33333 |
| Ensayo 2 | 1 | Insolubles en ácido | 0.183 | 0.007186 | 3.6995 | 3.92657 |
| Ensayo 2 | 1 | Fase Orgánica | 0.103 | 0.047000 | 24.1978 | 45.6311 |
| Ensayo 2 | 1 | Fase Acuosa | --- | 0.001500 | 0.77227 | --- |
| Ensayo 2 | 2 | Extracto | 5.006 | 0.153684 | --- | --- |
| Ensayo 2 | 2 | Insolubles en agua | 0.199 | 0.021000 | 13.6644 | 10.5528 |
| Ensayo 2 | 2 | Insolubles en ácido | 0.101 | 0.010299 | 6.70167 | 10.1974 |
| Ensayo 2 | 2 | Fase Orgánica | 0.124 | 0.039000 | 25.3767 | 31.4516 |
| Ensayo 2 | 2 | Fase Acuosa | --- | 0.001200 | 0.780822 | --- |
| Ensayo 3 | 1 | Extracto | --- | 0.251000 | --- | --- |
| Ensayo 3 | 1 | Fase Orgánica | 0.367 | 0.131000 | 52.1912 | 35.6948 |
| Ensayo 3 | 1 | Fase Acuosa | --- | 0.008000 | 3.18725 | --- |
| Ensayo 3 | 2 | Extracto | --- | 0.274000 | --- | --- |
| Ensayo 3 | 2 | Fase Orgánica | 0.33 | 0.101000 | 36.8613 | 30.6061 |
| Ensayo 3 | 2 | Fase Acuosa | --- | 0.005000 | 1.82482 | --- |
| Ensayo 4 | 1 | Extracto | --- | 1.029000 | --- | --- |
| Ensayo 4 | 1 | Fase Orgánica | 1.348 | 0.774000 | 75.2187 | 57.4184 |
| Ensayo 4 | 1 | Fase Acuosa | --- | 0.020000 | 1.94363 | NaN |
| Ensayo 4 | 2 | Extracto | --- | 0.912000 | --- | --- |
| Ensayo 4 | 2 | Fase Orgánica | 1.175 | 0.472000 | 51.7544 | 44.0463 |
| Ensayo 4 | 2 | Fase Acuosa | --- | 0.020000 | 2.19298 | --- |
# Limpieza de datos
df = df.replace('---', np.nan)
df[['Masa Total (g)','Rendimiento','Pureza']] = df[['Masa Total (g)','Rendimiento','Pureza']].astype('float')
df
| Repeticion | Fase | Masa Total (g) | Cantidad AC (g) | Rendimiento | Pureza | |
|---|---|---|---|---|---|---|
| Ensayo | ||||||
| Ensayo 1 | 1 | Extracto | NaN | 0.155571 | NaN | NaN |
| Ensayo 1 | 1 | Fase Orgánica | 0.104 | 0.009500 | 6.106544 | 9.134615 |
| Ensayo 1 | 1 | Fase Acuosa | NaN | 0.001000 | 0.642794 | NaN |
| Ensayo 1 | 2 | Extracto | NaN | 0.167895 | NaN | NaN |
| Ensayo 1 | 2 | Fase Orgánica | 0.185 | 0.013000 | 7.742958 | 7.027027 |
| Ensayo 1 | 2 | Fase Acuosa | NaN | 0.004000 | 2.382449 | NaN |
| Ensayo 2 | 1 | Extracto | NaN | 0.194233 | NaN | NaN |
| Ensayo 2 | 1 | Insolubles en agua | 0.132 | 0.011000 | 5.663316 | 8.333333 |
| Ensayo 2 | 1 | Insolubles en ácido | 0.183 | 0.007186 | 3.699499 | 3.926573 |
| Ensayo 2 | 1 | Fase Orgánica | 0.103 | 0.047000 | 24.197804 | 45.631068 |
| Ensayo 2 | 1 | Fase Acuosa | NaN | 0.001500 | 0.772270 | NaN |
| Ensayo 2 | 2 | Extracto | 5.006 | 0.153684 | NaN | NaN |
| Ensayo 2 | 2 | Insolubles en agua | 0.199 | 0.021000 | 13.664384 | 10.552764 |
| Ensayo 2 | 2 | Insolubles en ácido | 0.101 | 0.010299 | 6.701666 | 10.197427 |
| Ensayo 2 | 2 | Fase Orgánica | 0.124 | 0.039000 | 25.376714 | 31.451613 |
| Ensayo 2 | 2 | Fase Acuosa | NaN | 0.001200 | 0.780822 | NaN |
| Ensayo 3 | 1 | Extracto | NaN | 0.251000 | NaN | NaN |
| Ensayo 3 | 1 | Fase Orgánica | 0.367 | 0.131000 | 52.191235 | 35.694823 |
| Ensayo 3 | 1 | Fase Acuosa | NaN | 0.008000 | 3.187251 | NaN |
| Ensayo 3 | 2 | Extracto | NaN | 0.274000 | NaN | NaN |
| Ensayo 3 | 2 | Fase Orgánica | 0.330 | 0.101000 | 36.861314 | 30.606061 |
| Ensayo 3 | 2 | Fase Acuosa | NaN | 0.005000 | 1.824818 | NaN |
| Ensayo 4 | 1 | Extracto | NaN | 1.029000 | NaN | NaN |
| Ensayo 4 | 1 | Fase Orgánica | 1.348 | 0.774000 | 75.218659 | 57.418398 |
| Ensayo 4 | 1 | Fase Acuosa | NaN | 0.020000 | 1.943635 | NaN |
| Ensayo 4 | 2 | Extracto | NaN | 0.912000 | NaN | NaN |
| Ensayo 4 | 2 | Fase Orgánica | 1.175 | 0.472000 | 51.754386 | 44.046286 |
| Ensayo 4 | 2 | Fase Acuosa | NaN | 0.020000 | 2.192982 | NaN |
Propiedades del gráfico¶
Se pueden definir propiedades estéticas como dimensiones de figura, tipo de fuente, etc
# Propiedades del gráfico
plt.rcParams['figure.figsize'] = [10, 5]
font = {'family' : 'IBM Plex Sans',
'weight' : 'normal',
'size' : 15}
plt.rc('font', **font)
# Definición de DataFrame 'data' que solo contiene datos de interés
# además, se le eliminan las filas que tengan "Extracto" como fase, ya que no interesan para graficar
data = df.reset_index()[['Ensayo','Fase','Rendimiento','Pureza']]
for i, row in data.iterrows():
if row['Fase'] == 'Extracto':
data.drop(i, axis=0, inplace=True)
data
| Ensayo | Fase | Rendimiento | Pureza | |
|---|---|---|---|---|
| 1 | Ensayo 1 | Fase Orgánica | 6.106544 | 9.134615 |
| 2 | Ensayo 1 | Fase Acuosa | 0.642794 | NaN |
| 4 | Ensayo 1 | Fase Orgánica | 7.742958 | 7.027027 |
| 5 | Ensayo 1 | Fase Acuosa | 2.382449 | NaN |
| 7 | Ensayo 2 | Insolubles en agua | 5.663316 | 8.333333 |
| 8 | Ensayo 2 | Insolubles en ácido | 3.699499 | 3.926573 |
| 9 | Ensayo 2 | Fase Orgánica | 24.197804 | 45.631068 |
| 10 | Ensayo 2 | Fase Acuosa | 0.772270 | NaN |
| 12 | Ensayo 2 | Insolubles en agua | 13.664384 | 10.552764 |
| 13 | Ensayo 2 | Insolubles en ácido | 6.701666 | 10.197427 |
| 14 | Ensayo 2 | Fase Orgánica | 25.376714 | 31.451613 |
| 15 | Ensayo 2 | Fase Acuosa | 0.780822 | NaN |
| 17 | Ensayo 3 | Fase Orgánica | 52.191235 | 35.694823 |
| 18 | Ensayo 3 | Fase Acuosa | 3.187251 | NaN |
| 20 | Ensayo 3 | Fase Orgánica | 36.861314 | 30.606061 |
| 21 | Ensayo 3 | Fase Acuosa | 1.824818 | NaN |
| 23 | Ensayo 4 | Fase Orgánica | 75.218659 | 57.418398 |
| 24 | Ensayo 4 | Fase Acuosa | 1.943635 | NaN |
| 26 | Ensayo 4 | Fase Orgánica | 51.754386 | 44.046286 |
| 27 | Ensayo 4 | Fase Acuosa | 2.192982 | NaN |
# Gráfico de los rendimientos y pureza según prueba y fase, para los gráficos de pureza se descartan
# las filas de Fase Acuosa ya que no corresponden
fig = plt.figure()
def box_graph(df, key):
sns.boxplot(x='Fase',y=key, data=data, hue='Ensayo')
plt.ylabel('Rendimiento (%)')
plt.xticks(rotation=15)
plt.show()
box_graph(df,'Pureza')

# Redondeo los valores de cantidad total de AC
# Agrupo la data por Prueba y Fase, redondeo a tres decimales y exporto a un Excel
df['Cantidad AC (g)'] = np.round(df['Cantidad AC (g)'].astype('float'), 3)
group = df[['Cantidad AC (g)','Fase','Rendimiento','Pureza']].reset_index().groupby(['Ensayo','Fase'])
group = np.round(group.agg([np.mean,np.std]), decimals=2)
group = group.replace(np.nan, '---')
# Yapa: generar tabla de desviaciones
# Del nuevo DataFrame extraigo las columnas que quiero utilizar
columnas_de_interes = [i for (i,y) in group.columns.to_list()[::2]]
# Defino un nuevo Dataframe vacío, con las columnas definidas
# como las columnas de interés
means = pd.DataFrame(columns = columnas_de_interes)
for column in columnas_de_interes:
# Al nuevo DataFrame le asigna valores de
means[column] = group[(column, 'mean')].astype('str') + ' ± ' + group[(column, 'std')].astype('str')
means
| Cantidad AC (g) | Rendimiento | Pureza | ||
|---|---|---|---|---|
| Ensayo | Fase | |||
| Ensayo 1 | Extracto | 0.16 ± 0.01 | --- ± --- | --- ± --- |
| Fase Acuosa | 0.0 ± 0.0 | 1.51 ± 1.23 | --- ± --- | |
| Fase Orgánica | 0.01 ± 0.0 | 6.92 ± 1.16 | 8.08 ± 1.49 | |
| Ensayo 2 | Extracto | 0.17 ± 0.03 | --- ± --- | --- ± --- |
| Fase Acuosa | 0.0 ± 0.0 | 0.78 ± 0.01 | --- ± --- | |
| Fase Orgánica | 0.04 ± 0.01 | 24.79 ± 0.83 | 38.54 ± 10.03 | |
| Insolubles en agua | 0.02 ± 0.01 | 9.66 ± 5.66 | 9.44 ± 1.57 | |
| Insolubles en ácido | 0.01 ± 0.0 | 5.2 ± 2.12 | 7.06 ± 4.43 | |
| Ensayo 3 | Extracto | 0.26 ± 0.02 | --- ± --- | --- ± --- |
| Fase Acuosa | 0.01 ± 0.0 | 2.51 ± 0.96 | --- ± --- | |
| Fase Orgánica | 0.12 ± 0.02 | 44.53 ± 10.84 | 33.15 ± 3.6 | |
| Ensayo 4 | Extracto | 0.97 ± 0.08 | --- ± --- | --- ± --- |
| Fase Acuosa | 0.02 ± 0.0 | 2.07 ± 0.18 | --- ± --- | |
| Fase Orgánica | 0.62 ± 0.21 | 63.49 ± 16.59 | 50.73 ± 9.46 |